The web crawler automatically follows links it encounters in web page HTML. The web crawler makes requests to the web server just like the web application makes itself when users take certain actions. For example, when the crawler encounters a button in a form, the crawler submits a request for the button URI to the web server. These actions made by the web crawler could cause an undesirable effect. Examples
Many times our customers have a desire to exclude sensitive resources that they do not want to scan for any purpose. Sometimes these exclusions are based on URL data, and occasionally by IP address. Now you can define global exclusions across the whole subscription (all web applications), as well as exclude testing based on IP address. Learn more
It is best practice to define exclude/allow lists to ensure that parts of the web application will not be scanned/will be scanned. You can also add comments to aid users on why specific exclude list or allow list entries were created.
- Setup an exclude list to identify the URLs you do not want our service to scan. Any link that matches an exclude list entry will not be scanned unless it also matches a allow list entry.
- Setup an allow list to identify the URLs you want to be sure that our service will scan. When you setup an allow list only (no exclude list), no links will be crawled unless they match an allow list entry.
It is a good practice to define POST data lists to ensure blocking of form submission for POST requests in your web application as this could have unwanted side effects like mass emailing.
- Setup a POST data exclude list of entries to identify POST requests with body you want to block from form submission. Our service blocks form submission for any POST request with data that matches the specified entry and does not submit the blocked POST data (for example, form fields) during all scan phases. Example
It is good practice to define logout regular expression to ensure that the logout links of your web application will not be scanned.
- Setup the logout regular expressions to identify the logout links you want to exclude form scanning. Any link that matches the logout regular expression entry will not be scanned.
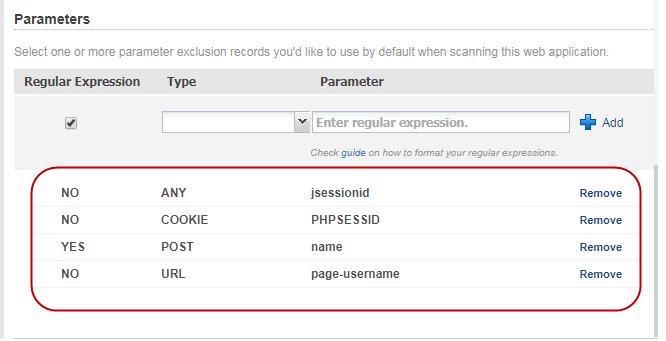
It is a good practice to define parameters to ensure that the parameters will be excluded from testing to improve a scan’s efficiency and effectiveness. Exclusions can be defined for URL parameters, request body parameters, or cookies.